EPPI-Reviewer 4: software for research synthesis
EPPI-Reviewer 4 is the EPPI Centre's comprehensive online software tool for research synthesis. It is a web-based software program for managing and analysing data in literature review and has been developed for all types of systematic review such as meta-analysis, framework synthesis and thematic synthesis.
Systematic review
EPPI-Reviewer 4 has the functionality to help manage your systematic review through all stages of the process from bibliographic management, screening, coding and right through to synthesis.
It manages references, stores PDF files, facilitates qualitative and quantitative analyses and allows easy export of review data to enable use with other software programmes.
The software allows multiple concurrent users to access the system and being web-based allows members of a review group to be located in different geographic locations.
|
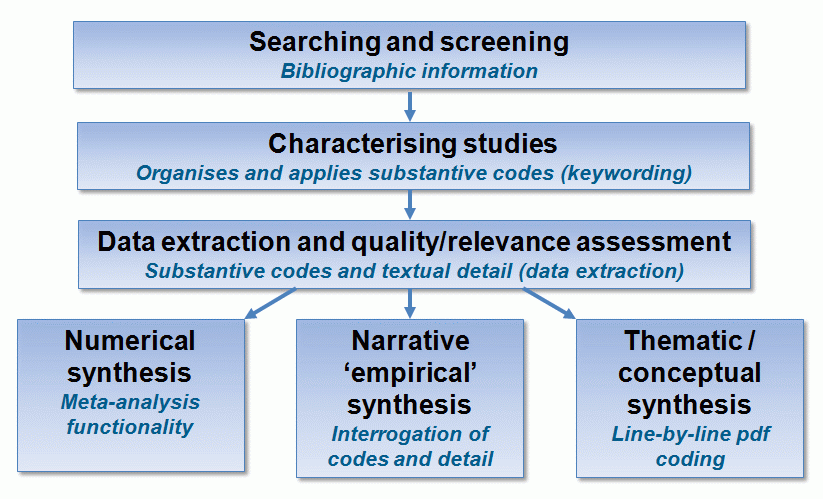 |
EPPI-Reviewer 4 supports many different analytic functions for synthesis including meta-analysis, empirical synthesis and qualitative thematic synthesis. It allows you to present your data in summary diagrams and customisable reports.Recent additions to the software include text mining, data clustering, classification and term extraction which are leading to new possibilities in the field of systematic reviewing.
The only system requirements to run EPPI-Reviewer 4 are that you must be connected to the internet and your computer will need to have the free Microsoft Silverlight browser plug-in installed. This plug-in is available for both PCs and Macs and is available here.
You can start using EPPI-Reviewer 4 today by signing up for a free one month trial here!
Detailed features and functions
| |
|
|
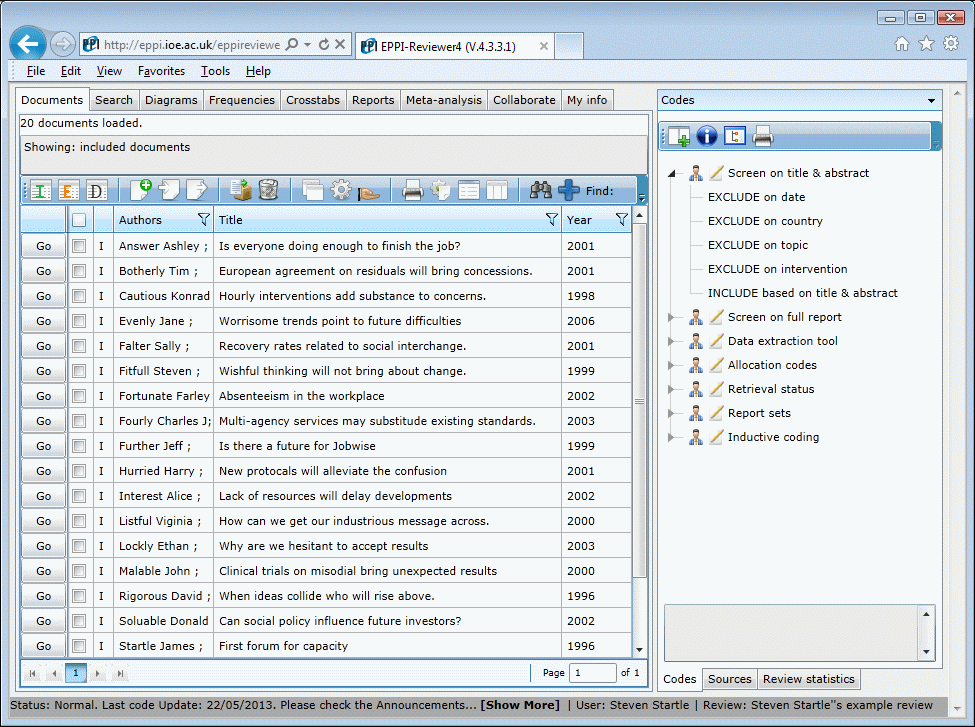
Reference management
- Managing the thousands of references that often result from comprehensive searches of electronic databases
- Importing references in a wide variety of 'tagged' formats incl. direct searching of resources such as PubMed and Microsoft Academic
- Duplicate checking using 'fuzzy logic'. (Potential duplicates can be checked manually and / or automatically classified as duplicates, depending on how similar they are.)
- Document storage: store the original document file (such as pdf, doc etc) along with the study record.
|
 |
| |
|
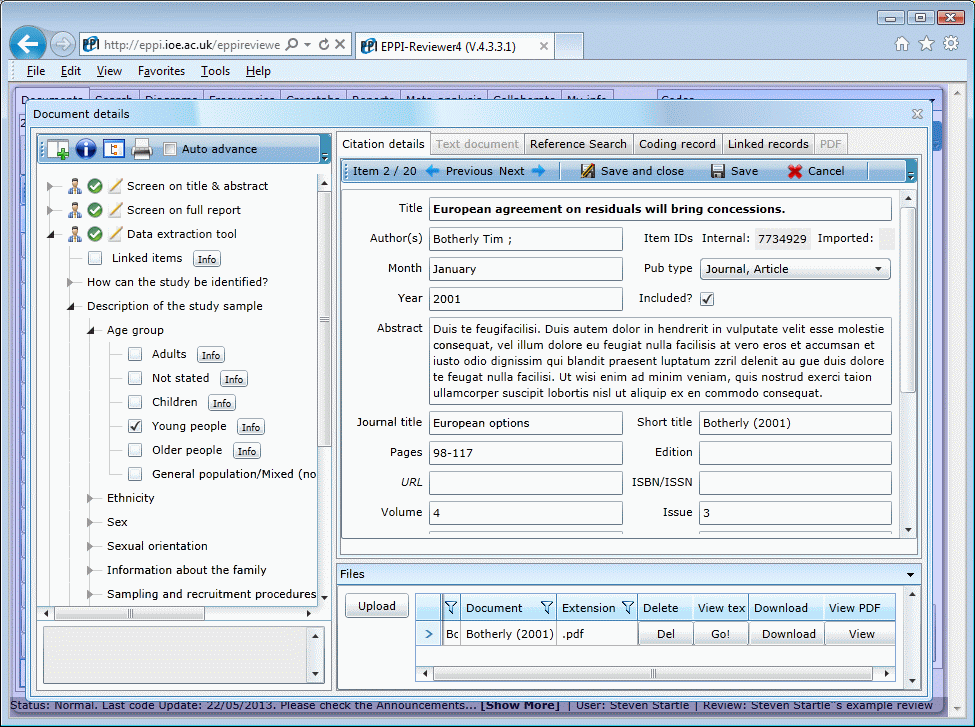 |
Study classification and data extraction
- Flexible coding schemas for classifying studies:
- Inclusion / exclusion / eligibility criteria;
- Codes for descriptive 'mapping' of research activity.
- Codes to capture detailed information about a study.
- Concurrent multi-user classification: multiple users can classify studies independently and then compare their results; EPPI-Reviewer 4 assists through the process, producing discrepancy reports and an interface to facilitate the process of agreeing final decisions.
- Bulk application / removal of codes to selected studies
- Calculation of common measures of effect (odds ratios, risk ratios, risk differences, standardized mean differences, mean differences) from a variety of statistics (2 x 2 tables, means, standard deviations, confidence intervals, p, t and r values).
- Text mining: automatic term recognition and document clustering.
|
| |
|
|
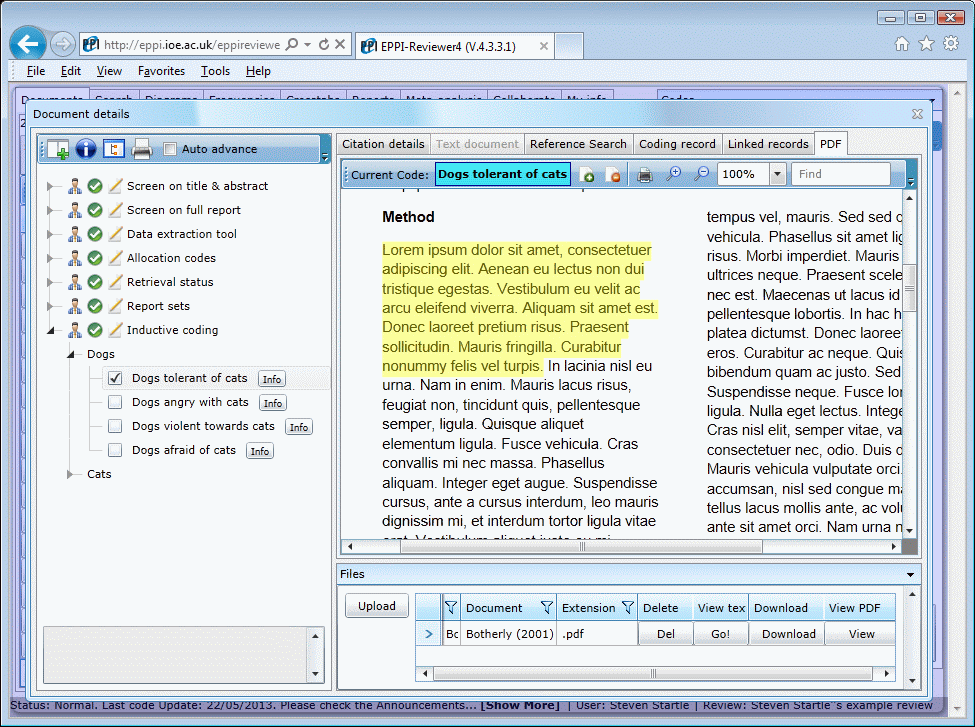
Synthesis
- Running meta-analyses (fixed and random effects models); calculating I-squared and supporting sub-group analyses using analog to the anova
- A powerful search engine enabling users to search by categories and text and combine searches using Boolean terms
- Producing reports of categorical, numeric and textual data in a wide variety of formats from frequency reports, crosstabs and full-text reports, to tabular summary reports and summary statistics of numeric data
- Text mining functionality. Automatic document clustering, using text mining, is one way of describing the range of studies you have identified at the click of a button. Text mining can assist with searching by identifying significant terms in the documents you have already included.
- Inductive coding functionality. This allows line by line coding of textual data and organising and structuring these codes graphically into ‘conceptual relationship diagrams to display analytic and descriptive themes found through inductive coding.
- Fulltext reference searching using the uploaded pdfs.
- Diagrams to summarise e.g. qualitative syntheses and theories of change for interventions.
|
 |
| |
 |
Review Management
- The ability to create an unlimited number of non-shareable reviews.
- Allocation of classification tasks (e.g. screening / data extraction) to individual users.
- Work progress reporting.
- Individual reviewer permissions (forthcoming)
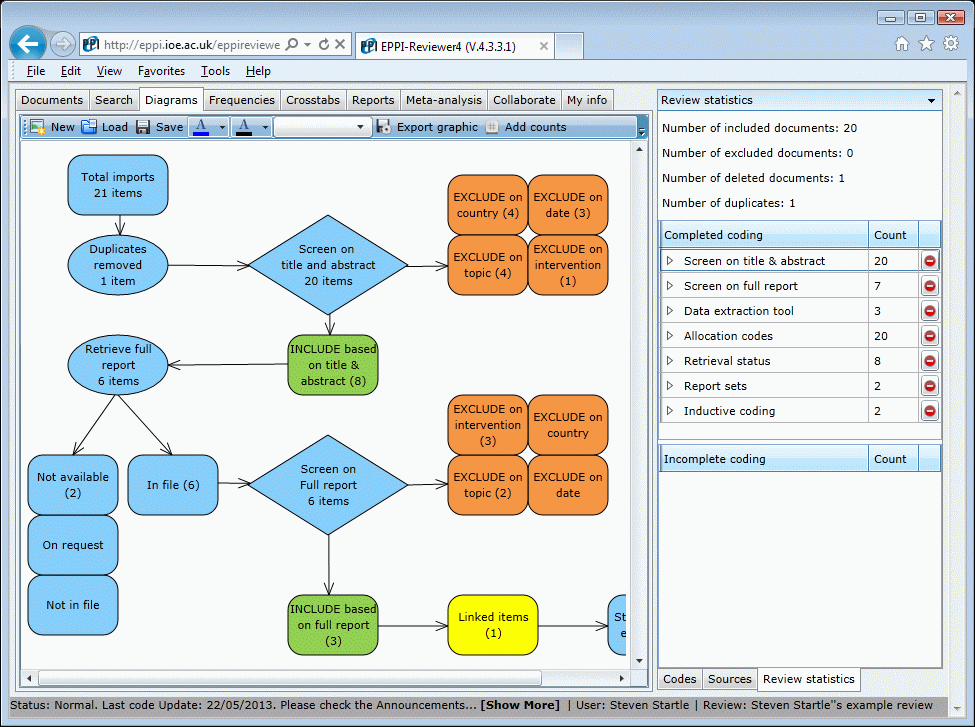
- Review flow charts which update automatically (e.g. with counts of how many studies have been included / excluded according to which criterion in order to generate PRISMA flow-diagrams).
- Easy export of review data to enable use with other software programmes and to enable long term independent storage of data.
|
Under development
We have been developing ways of using emerging text mining technologies in systematic reviews. Currently used during the searching and screening stages of a review, you can read a paper which outlines their potential published in Research Synthesis Methods*. We have also written up our early findings in the NCRM Newsletter and in a poster presented at the 2011 Cochrane Colloquium. Methods to use these technologies are still in their infancy and require significant further evaluation. While automatic term recognition and document clustering are available for all users, document classification often requires significant server processing time and support; therefore this technology is not yet generally available in EPPI-Reviewer. However, if you would like to use a classifier in your review, please contact us to discuss your particular requirements.
* Thomas J, McNaught J, Ananiadou S (2011) Applications of text mining within systematic reviews. Research Synthesis Methods 2: 1-14
Citing EPPI-Reviewer 4
Thomas J, Brunton J, Graziosi S (2010) EPPI-Reviewer 4: software for research synthesis. EPPI Centre Software. London: Social Science Research Unit, UCL Institute of Education.